

Scraping websites is one of the easiest ways of gathering online data. Web scraping is the process of automatically retrieving information from websites.
One sector where web scrapers are used intensively is e-commerce. Shopping, auctioning, and marketplace websites are some of the most scraped sites on the Internet.
Who scrapes e-commerce websites:
- Search engines – they scrape e-commerce websites for listing product information on their result pages when somebody searches for them
- Competition – it’s well known the fact that competitors scrape each others’ sites to retrieve data on available stocks, pricing, and promotions
- Comparison platforms – e-commerce players that scrape pricing of the same product on different platforms to find the best prices
What is Beagle Scraper
Beagle Scraper is a fully-customizable e-commerce scraper that can be adapted to scrape data from any e-commerce website.
The scraper is built with Python and beautifoulsoup4, making it easy to learn and to adapt to your needs.
Beagle Scraper can be customized to retrieve data from Amazon for price analysis, or it can be used to scrape pricing information from both Amazon and Bestbuy and find price discrepancies and opportunities.
How did Beagle Scraper start
I started Beagle Scraper as a learning-to-code project after I finished the Codecademy course on Python.
While the Python course was straight-forward, and it helped me grasp the basic principles of coding, I needed a project of my own to fully understand coding and the thinking behind developing a coding project.
I’ve always been fascinated by data mining and automating tasks, so I thought that the best way I could learn is by developing a project I enjoyed. Fast-forward three months of coding a couple of hours a day, I end up with Beagle Scraper – a fully-customizable e-commerce scraper.
Advantages of using Beagle Scraper over ready-made scrapers
Beagle Scraper is fully functional, but you shouldn’t consider it an out of the box tool because it is not. It was never intended to be. And this is how it will continue to be.
Here are 3 advantages (and reasons) why Beagle Scraper will remain as it is:
- Granular control and adaptability – you can always choose what data you want to retrieve from e-commerce websites. Also, you can choose to modify the scraper so you can use it not only on Amazon but also on eBay or even StockX.com
- Improve coding skills – this is the main reason for which Beagle Scraper was started. You can use it to improve your coding skills and build on top of it. Maybe you want to create a GUI or to do real-time price analysis; there’s no limit to what you can do and learn by playing with it.
- Learn how web scraping works – from cookie management to headers used, scraping data online involves several moving elements that you need to bring together for a scraper to work.
How to use Beagle Scraper
There is no need for you to use any particular operating system. The scraper doesn’t need an actual machine install, just download the files from GitHub and run it on a Windows PC, Linux machine, VPS or Mac.
Requirements needed to run:
Possible extra dependencies required
Depending on what Python version and dependencies you have previously installed, sometimes, Beagle Scraper might ask for other secondary Python libraries.
In general, you shouldn’t be prompted to install something else, but just in case you need to install them, you can easily use the pip command:
> pip install [missing package name]
Only replace [missing package name] with the package that Python terminal prompted you that is required.
Run Beagle Scraper
Beagle Scraper doesn’t have a GUI, but it uses files as a way to manage the scraper without actually modifying the code.
Here’s how you can run the scraper after you have downloaded it on your machine:
1. Create a text file called “urls.txt“, in the same folder where you downloaded the scraper files, and insert Amazon product category links (each link on a new line)
2. Start the scraper by running the command
> python start_scraper.py
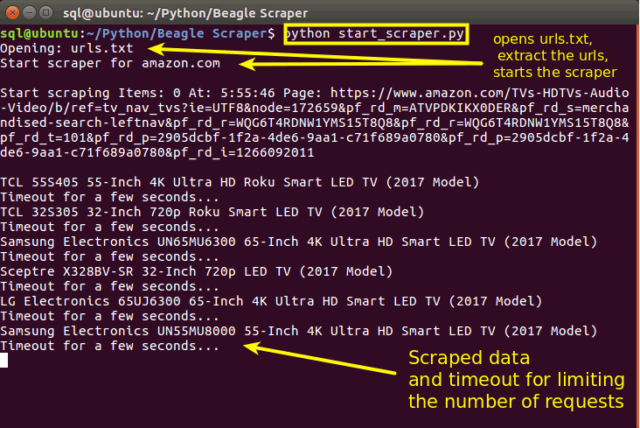
3. Once Beagle Scraper finishes the job (it will scrape the whole category, even change pages where there is more than one page of products), search in the scraper folder for the JSON file:
amazon_dd_mm_yy.json
Where the dd_mm_yy will be replaced with the current date of the scraping job)
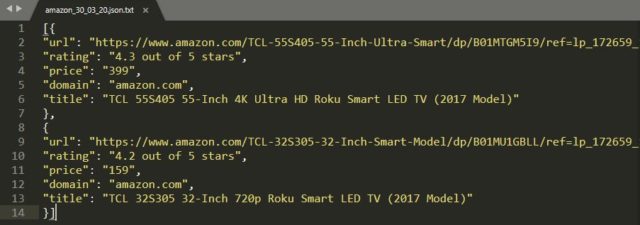
In this file are the results (data scraped) of the current job.
Use proxychains/Proxifier
Almost all e-commerce websites have a rate-limiting feature set in place to limit the number of web requests automatic tools can perform on a given time.
For example, if you send multiple requests to access numerous pages from the same website at the same time, the targeted site will identify your requests as coming from the same IP address and will block some of them.
There are a couple of things you can do to avoid this block:
- (The most important) Don’t spam! Use a timeout function between your requests so the scraper won’t overload the e-commerce website with requests – this is the ethical thing to do, and you should always avoid abusing a web server.
- Use proxies after you set your timeout so that you won’t risk a temporary block of your IP (some websites after a set amount of requests will limit or temporarily block all requests coming from an IP address). To avoid this, you need proxies and a proxy management tool, such as Proxychains (for Linux) or Proxifier (for Windows and Mac machines)
However, you won’t need proxies or a proxy management tool if you use Beagle Scraper to learn how to code and scrape one page every few minutes. Given that you will tweak the scraper and send a few requests for testing every few minutes, you can do this by using your IP address without risking a block.
On the other hand, if you plan on using Beagle Scraper in production, you will need to use proxies to avoid any IP blocks when your scraper accesses whole product categories for more extended periods.
Proxifier for Windows and Mac has a GUI and is quite easy and intuitive to use. But, for Linux, Proxychains is a terminal-based tool, so after you installed it, you have to add the proxychains keyword before the start_scraper.py command like this:
> proxychains python start_scraper.py
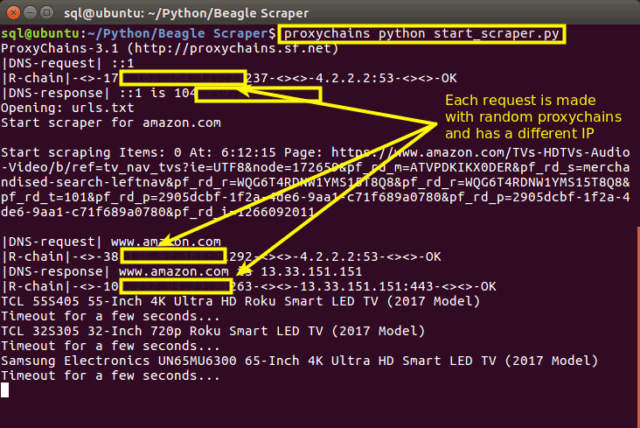
In this way, all your requests are sent through the proxies you set in Proxychains, and you’ll avoid any temporary blocks.
How to modify Beagle Scraper
This is the fun part. You can find a guide on how to modify the scraper here.
If you plan on building on top of the current code base, you can open the start_scraper.py file and modify it for retrieving the e-commerce data you need.
Alternatives to Beagle scraper and scraping
This scraper and all other scrapers are a great way to start learning to code. But, further down the road, you might want to develop your coding skills further, or you’ll need more data retrieved.
If you don’t want to get data via a scraper, you can use Amazon’s API. For which you can get access by signing it to AWS. However, using API calls comes with a price tag. So, before using their API, check their pricing model to understand how much it will cost you.
In conclusion
Beagle Scraper, which started as a learning project, can be used to either scrape e-commerce data from Amazon, from other e-commerce websites or to improve your coding skills. It can be easily modified and adapted to other e-commerce platforms or can be a stepping stone to building more complex scrapers.