Advancement is something that has never come to an end. Everything around us is evolving and getting better day by day. Same is the case with the speech synthesizing. It is an old field of research which has regained a fresh boost from Fujitsu’s new synthesizing technology. Fujitsu is a well-known Japanese tech giant. A system is being developed by Fujitsu to move the computers away from monotonic sound production. Voice with excellent quality can be produced according to the circumstances and environments.
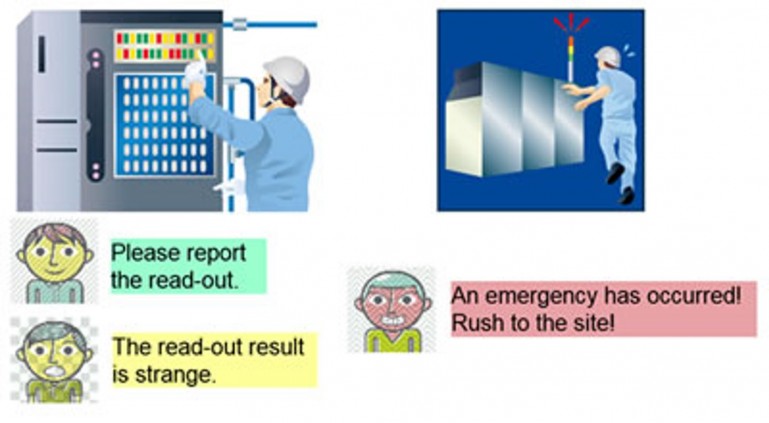
Speech synthesizing is a futuristic technology that is not just limited to chatting with a smartphone assistance app but has plenty of applications. It could be used for providing the emergency information, reading the traffic signals, travelling information at railways and airports, and helping the drivers to move around the globe. The basic requirement for the speech synthesis is its natural soundness. It must look as being generated by some human being. Whenever, one need to synthesize some code into speech or some text into speech, the requirement is same. Working appropriately and robustness are also other main objectives but not all.


The speech synthesis technology is a tradeoff between how fast the algorithm generates output or how much accurate it is? Even, if an optimal tradeoff is achieved still there are some other issues to be dealt with. Whatever synthesizing method is used, it must give the feeling of a natural voice. The lack of feelings sometimes annoys listeners. Suppose your credit of mobile has come to an end and the announcement is very cheerful. How does it sound to you? It would be annoying and one would surely get angry at such tones. Proper synthesis technique should also ensure that voice must be clearly understood in the noisy environment or over long distance.
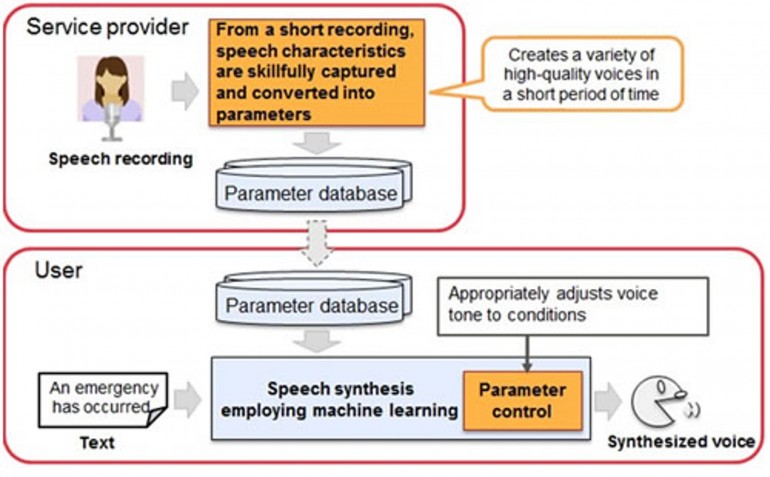
Fujitsu has done a marvelous job in this regards, they changed the strategy of synthesizing. They broke down the synthesis into small basic units of speech, and then adjusted the parameters like pauses and intonation accordingly. This method has reduced the time of speech producing by 1/30 times. Its same like someone is using English characters and other one is using Chinese characters. The English characters are written more easily and quickly than Chinese requiring simple keyboard. Instead of using a large amount of libraries, a small algorithm, based on machine learning, is used to save cost and time. Fujitsu is hoping to launch full version of this algorithm by the end of this year.